

Abstract
Anticipation of a road user’s intention is one of the major challenges for safe assistive and autonomous driving in urban environments. While existing research in this area focuses on pedestrian crosswalk behavior, other vulnerable road user (VRU) behaviors such as cyclist hand signs are underexplored. To understand behavior of VRUs, it is important to recognize human action in driving scenario. To address this, we first introduce the FUSE-Bike, a custom open-source bicycle platform equipped with two LiDARs, one camera, and a GNSS for capturing close-range VRU action perception with precise localization. Using this platform, we present bikeActions, a novel skeleton-based human action classification dataset consisting of approximately 850 action sequences annotated with 5 distinct action classes. We then provide a comprehensive benchmark with state-of-the-art graph convolution and transformer-based human action classification models. To encourage researchers to investigate VRU action understanding, we will release the dataset, the bicycle platform design, and all related code.
Method
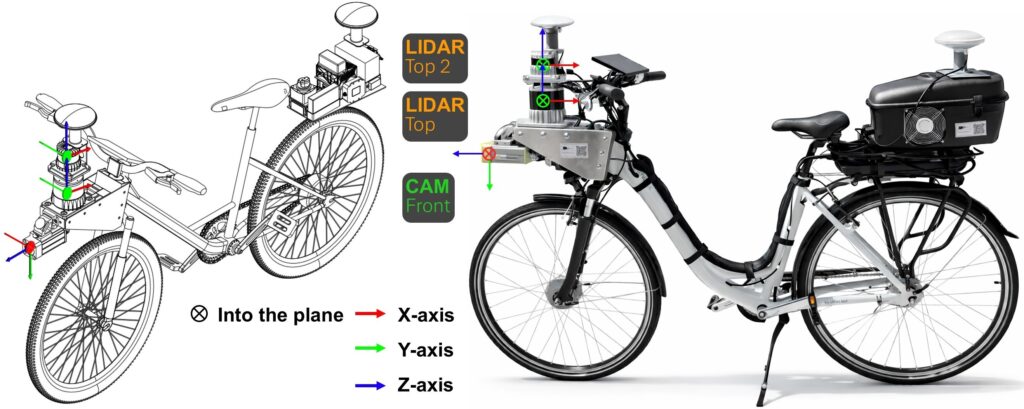
The FUSE-Bike Platform: A New Perspective on Urban Perception
To truly understand how vulnerable road users (VRUs) like pedestrians and cyclists behave, we need to see the world from their perspective. Existing data collection platforms are almost exclusively car-based, which limits their ability to capture the close-quarters, nuanced interactions that are critical for safety.
To solve this, we designed and built the FUSE-Bike, a novel, open-source perception platform built on a bicycle. It features a high-fidelity sensor suite, including:
- A high-resolution RGB camera
- Two 3D LiDARs (long-range and near-field)
- A dual-antenna RTK-GNSS module for precise localization
Critically, all sensors are synchronized at the hardware level using the Precision Time Protocol (PTP), ensuring all data shares a common time base with microsecond-level accuracy. The complete hardware design, software stack (ROS2), and calibration routines will be made publicly available to foster further research.
The bikeActions Dataset: A New Benchmark for VRU Actions
Using the FUSE-Bike, we created bikeActions, a new multimodal dataset focused specifically on urban human action recognition. The dataset addresses a key gap in the field: existing driving datasets lack fine-grained action labels, while general action datasets lack the context and sensor data of real-world traffic.
Key Features of bikeActions:
- Total Samples: 852 annotated action sequences.
- Total Frames: 46,180 raw, synchronized frames of camera and LiDAR data.
- Unique Viewpoint: All data is captured from a cyclist’s perspective, providing a unique view of VRU interactions.
- Rich Annotations: We provide dense annotations for 9 action classes, including walk, stand, bike, left, right, and wave. Each sample includes 3D skeletons in the global coordinate frame.
- High-Quality Labeling: Annotations were created using our custom-built, open-source annotation tool, which combines automatic suggestions with manual refinement to ensure consistency and accuracy.
Benchmarking State-of-the-Art Models
A new dataset requires a new baseline. To establish the first performance benchmarks on bikeActions, we trained and evaluated five state-of-the-art, skeleton-based action recognition models:
- Hyperformer
- HD-GCN
- CTR-GCN
- Koopman
- SkateFormer
We analyzed the performance of these models across multiple input modalities (joint, bone, joint motion, etc.). Our results provide a comprehensive baseline for this new and challenging task, and we release our training and evaluation code to allow for direct comparison and future work in VRU action understanding.

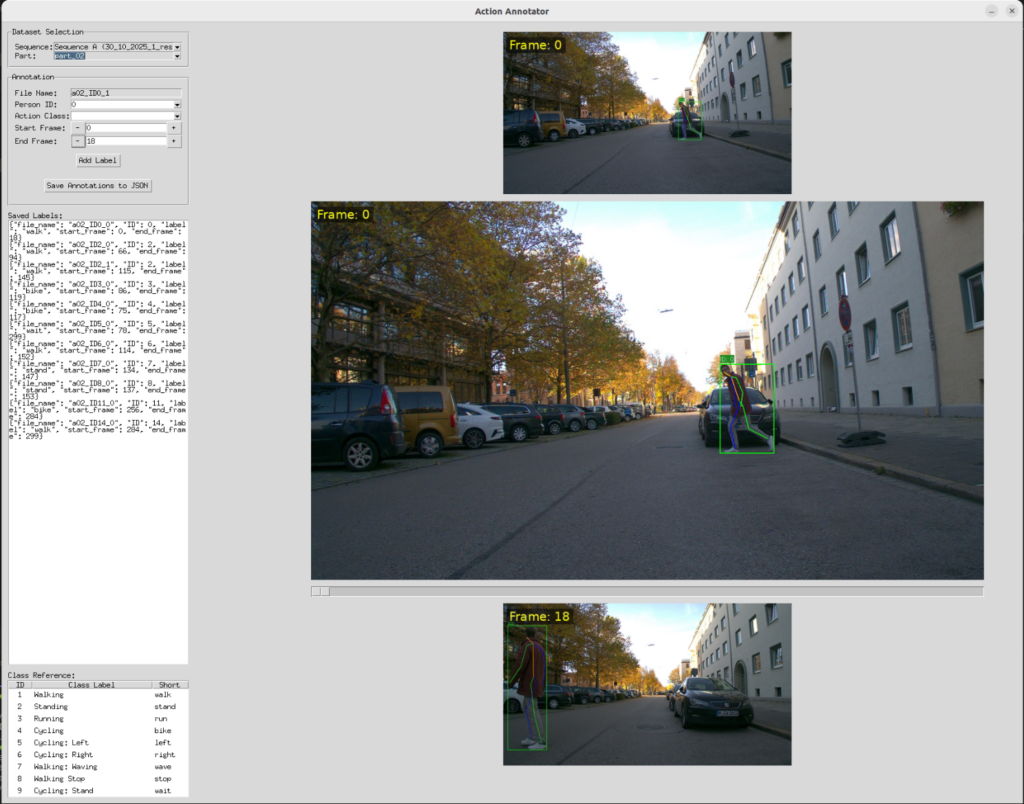
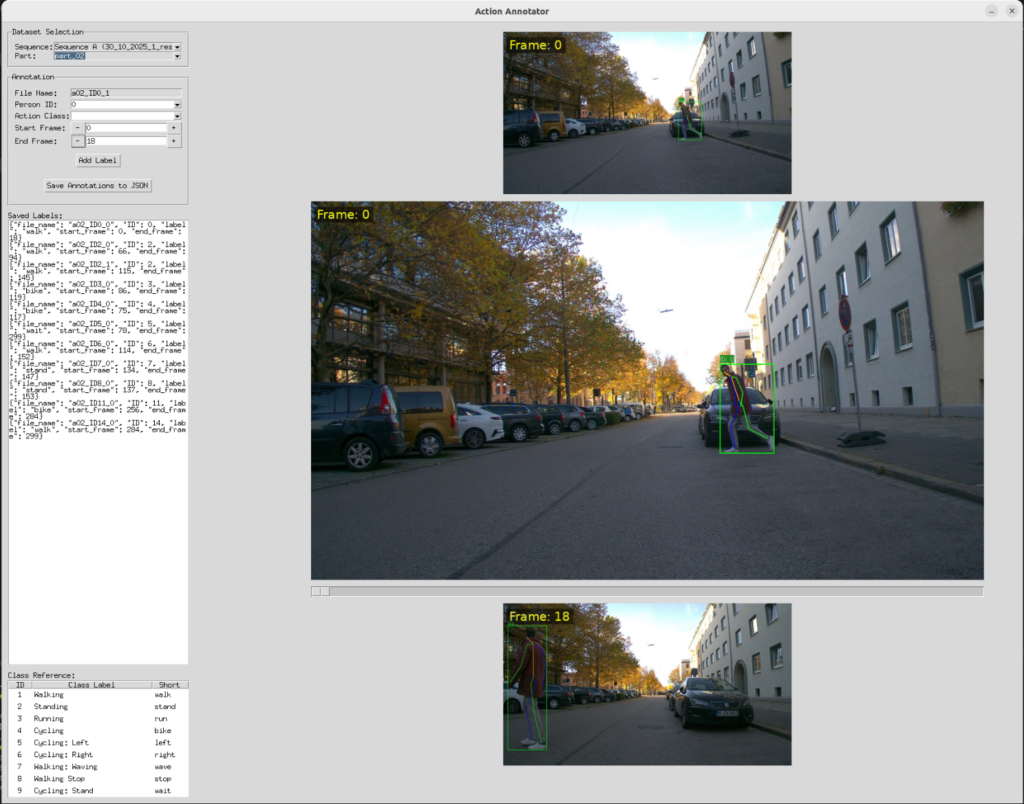
Annotation Tool
We developed a custom annotation tool because existing solutions are ill-suited for the precise temporal labeling of actions for multiple tracked individuals. The application presents an interactive three-frame view (start, middle, end) with a scrubbing slider, allowing an annotator to quickly verify and refine the duration of an action before assigning a class label.
Citation
@conference{icpr,
title = {bikeActions: Action Classification Dataset for Behavior Understanding of Vulnerable Road Users},
author = {Buettner, Max A. and Mazumder, Kanak and Koecher, Luca and Finkbeiner, Mario and Niebler, Sebastian and Flohr, Fabian B.},
booktitle = {},
year = {2026},
}