Autonomous driving has the potential to set the stage for more efficient future mobility, requiring the research domain to establish trust through safe, reliable and transparent driving. Large Language Models (LLMs) possess reasoning capabilities and natural language understanding, presenting the potential to serve as generalized decision-makers for ego- motion planning that can interact with humans and navigate environments designed for human drivers. While this research avenue is promising, current autonomous driving approaches are challenged by combining 3D spatial grounding and the rea- soning and language capabilities of LLMs. We introduce BEV- Driver, an LLM-based model for end-to-end closed-loop driving in CARLA that utilizes latent BEV features as perception input. BEVDriver includes a BEV encoder to efficiently process multi- view images and 3D LiDAR point clouds. Within a common latent space, the BEV features are propagated through a Q- Former to align with natural language instructions and passed to the LLM that predicts and plans precise future trajectories while considering navigation instructions and critical scenarios. On the LangAuto benchmark, our model reaches up to 18.9% higher performance on the Driving Score compared to SoTA methods.
Video
Method Architecture
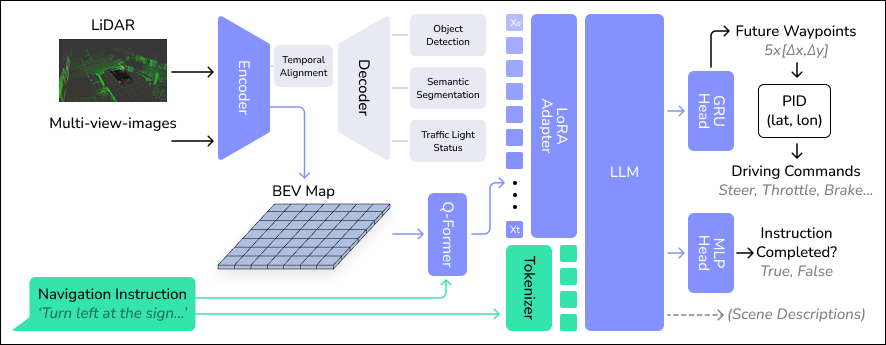
Architecture of BEVDriver. Multi-view RGB images and 3D LiDAR point clouds are encoded into a BEV feature map, trained with object detection, semantic segmentation, traffic light detection and a self-supervised alignment loss. A Q-Former aligns the pre-trained latent features with the navigation instructions natural language space. A LoRA adapter feeds historical inputs to the LLM, which processes tokenized navigation instructions alongside perception data. The LLM outputs future waypoints, converted into driving commands by a PID controller, as well as scene descriptions and a boolean indicating instruction completion.
Important Links
Paper (arxiv): https://ieeexplore.ieee.org/document/11247237
Github: https://github.com/intelligent-vehicles/BEVDriver
Cite this:
@INPROCEEDINGS{11247237,
author={Winter, Katharina and Azer, Mark and Flohr, Fabian B.},
booktitle={2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
title={BEVDriver: Leveraging BEV Maps in LLMs for Robust Closed-Loop Driving},
year={2025},
volume={},
number={},
pages={20379-20385},
keywords={Point cloud compression;Three-dimensional displays;Laser radar;Navigation;Benchmark testing;Turning;Cognition;Robustness;Trajectory;Autonomous vehicles},
doi={10.1109/IROS60139.2025.11247237}}
Acknowledgement
The research leading to these results is funded by the German Federal Ministry for Economic Affairs and Energy within the project “NXT GEN AI METHODS – Generative Methoden für Perzeption, Prädiktion und Planung”. The authors would like to thank the consortium for the successful cooperation

